
很多人开始用 AI 做长视频,基本都卡在同一个地方:单次最多生成 15 秒。
想做完整广告只能拼,一拼就出问题:人脸漂移,动作跳帧,前后场景对不上。
换工具没用,从 Seedance 换到 Kling 换到 Hailuo,结果一样,15 秒已经是AI生成视频的上限,只能少不能多。
更难的问题是,大多数人每段都单独出图,人物长相、光线、场景风格全不统一,拼起来比不拼还碎。
我们团队成员用这套方法论做出了第一条 AI 长视频——Laura Geller 口红广告「涂上它,然后开口」,四个年龄段女性,从 20 岁到 60 岁,成片 115 秒,全 AI 生成,没有一帧是真实拍摄的。

如果你也在AI生成长视频这个问题上卡过,我把方法论整理在这里了。每步先说思路,再说我们实际怎么做的。
## 01 资产前置——人物、场景、产品、音色,分开备设定
所有一致性问题的根源都在这里没做好。
不同项目要备的设定不一样,先说基础的四类:
- 人物设定:出一张有正面、侧面、背面的人物全身三视图。正面额外出一张半身版,给近景镜头单独用。表情至少 3 种,比如自然闭嘴、微笑、专注皱眉,对应视频里不同情绪段落。服装和配饰单独出细节图,模型在不同段之间容易漂移,衣领、袖口、配饰有参考图才能锁住。
- 场景设定:先出无人的空景,固定光线和色调。同一个场景按景别分开出三张:全景(交代整个空间)、中景(人物位置与环境的关系)、近景(专注人物或物品细节)。还有一个进阶做法:先生成一段360°场景环视视频,生成人物镜头时附上这段视频并在提示词里写明站位,实测有效。
- 产品设定(带货产品):正面图(包装完整、无遮挡)、侧面图(能看清色柱或材质)、45 度斜侧图(能同时看到正面和侧面,最常用)、产品被拿起或使用中的状态图、logo 和品牌字体的特写(结尾打品牌名时用)。
- 音色设定:旁白音色和人物对白音色分开定,不能混用。选好后出一段 30 秒样本试听确认,存档音色 ID,全片统一用同一声音,中途不能换。
工具上从性价比出图可以用买免费的豆包,适合低成本大量试错,追求质量直接上 Image2。音色设计用 ElevenLabs、 TTS、MiniMax,当然也有客户直接找真人配音,按分钟计费,成本反而更可控。
我们怎么做的:
四位主角分别是 20 岁宿舍女生、30 岁职场女性、35 岁会议室女性、45 岁梳妆台女性,加尾段 60 岁老奶奶。每人额外出了一张嘴唇涂口红的特写图,留给汇聚分镜用。
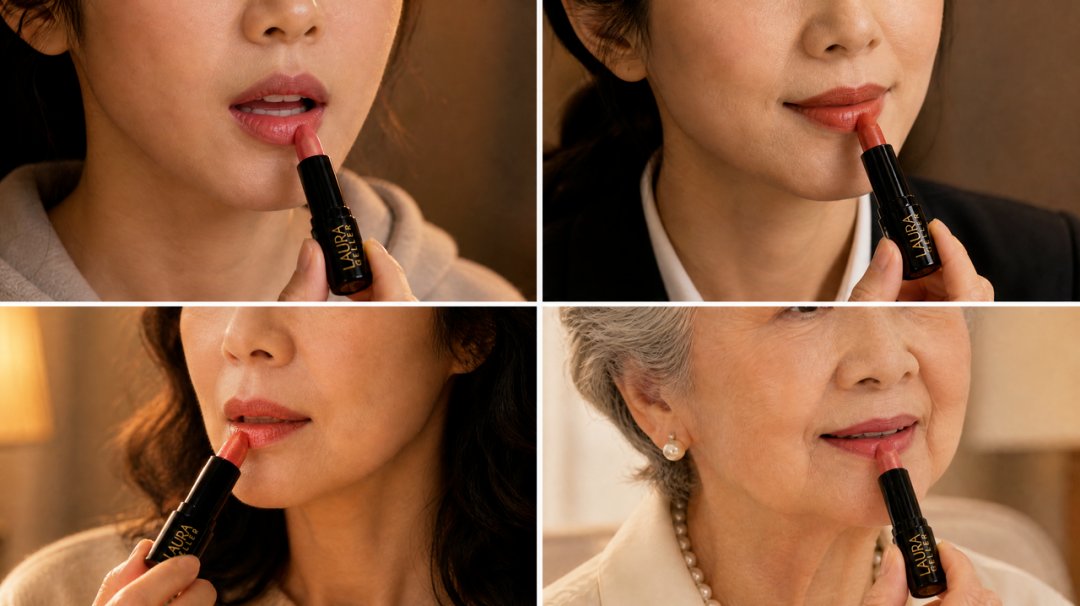
产品是 Laura Geller 口红,出了粉色/砖红/珊瑚金三个颜色,每个颜色各自出正面、侧面、45 度、旋开状态四张,logo 特写单独一张留给收尾。

场景出了四套空景:宿舍、写字楼洗手间、会议室、家居梳妆台,分别出了全、中、近三个景。旁白音色定为女声,30-40 岁感,低沉温柔,语速克制,非甜美型,存档 30 秒样本。备好设定,下一步进分镜。
## 02 脚本规划——定叙事结构,镜头标清六件事
叙事结构先定,任何视频都需要一个让人从头看到尾的理由。跨境电商广告的通用逻辑是:痛点 → 产品出现 → 效果证明 → 行动号召
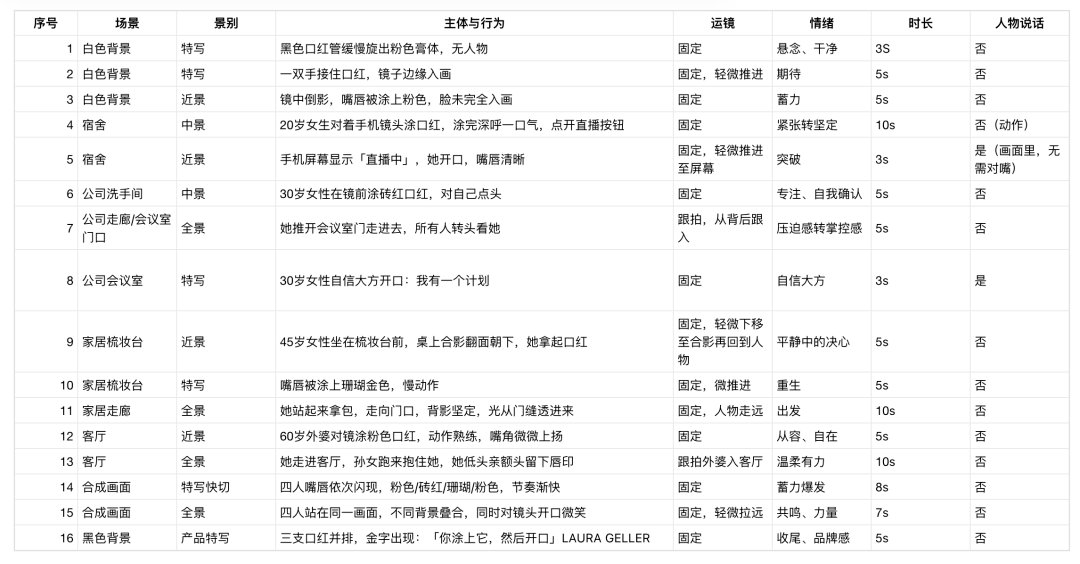
每个镜头要标清楚六件事:
1. 1. 景别(全/中/近/特写)
2. 2. 主体行为
3. 3. 运镜方式(固定/推进/拉远/跟拍)
4. 4. 情绪氛围
5. 5. 预计时长
6. 6. 有没有人物说话(这条决定音频怎么处理)
建议每个镜头的时长标准:特写或静态镜头出 5 秒,有人物动作的中景 5-10 秒,需要完整交代信息的 10-15 秒。基本上能拆就拆,时长越短利用率越高,切镜头比强行拉长更自然,质量也更容易控制。
分镜脚本可以用DeepSeek 、Gemini 生成。
我们怎么做的:
叙事结构改成:产品出现(悬念)→ 四个女人的故事(共鸣)→ 嘴唇汇聚(升华)→ 产品收尾(转化)。一共 15 个镜头,我们初定的分镜表大致如下:
## 03 分镜生视频——三种方式,按镜头类型选
根据镜头类型选方式,不要所有镜头都用同一种。
方式一:纯提示词。
适合开场、全新场景切入、不需要从前一段画面连过来的镜头。第一步备好的参考图(人物图/场景图/产品图)照常用,区别是这段可以独立生成,不依赖上一段的尾帧。
提示词结构:主体+行为+景别+运镜+风格约束+禁止项。禁止项必须写,比如「禁止迁移参考图的画面风格」,防止模型乱引用参考图的整体风格。
方式二:分镜模式。
也就是故事板(Storyboard)生成方式。一个提示词里描述多个画面,一次生成六宫格或九宫格,每格是一个关键帧。挑出最好的帧组合拼接,或直接把关键帧转成短视频片段。适合多镜头快切、产品多角度展示这类不需要强连续的段落。
方式三:尾帧衔接。
适合剧情连续、人物动作延续的镜头。操作:生成上一段 → 导入剪辑软件导出一次(统一编码)→ 截最后一帧 → 用这帧+新提示词生成下一段 → 拼接时删掉下一段开头 1-2 帧,防止卡顿。
首尾帧的用法大家都不陌生,但有一点容易踩坑:不能直接截尾帧就拿去做下一段的首帧,衔接处会有明显色差和跳变。所以需要把上一段导入剪映、PR等导出一次,用导出后的尾帧做下一段首帧,再拼接时删掉下一段开头 1-2 帧防止卡顿。
工具可以用Nano Banana、Image2、甚至豆包出分镜图,视频用Seedance 2.0、Veo 3.1图生视频效果比较好。
我们怎么做的:
宿舍直播那段走的是方式一,20 岁女生涂口红→深呼一口气→点直播按钮,三个动作一个镜头带完。

走廊那段走的是方式三,逆光从门缝透进来的效果在提示词里单独写了,不然模型默认平光。





## 04 剪辑拼接——按逻辑选转场,拼接不生硬
视频段都生成完了,下一步是拼装。这一步看起来是剪辑拼接,但是太生硬或者转场选错,前面做得再好也会显得割裂。
常用的转场选择逻辑:
- 同场景、景别接近 → 硬切
- 跨场景 → 叠化(0.5 秒以内,不要拖)
- 情绪转折 → 闪白/闪黑
- 两段明显拼不上 → 补生成 2-3 秒过渡镜头,不靠特效掩盖
这些只是参考,转场最终还是审美判断,同一个衔接点用硬切还是叠化,没有标准答案,多出几个版本对比才知道哪个顺眼。
剪辑顺序:按分镜顺序拼素材 → 逐个检查衔接点处理卡顿、穿帮、色差 → 加字幕 → 最后配音频。不要提前配音,剪辑过程中时长会变。
我们怎么做的:
15 个镜头,转场分布大概是这样的:开场三个白色背景镜头全是硬切,光线统一,直接切最干净;三段故事之间用闪黑 0.3 秒隔开,段落感更明确;08→09 梳妆台近景切嘴唇特写、09→10 嘴唇特写切走廊全景,两处景别跨度都很大,各加了 0.5 秒叠化;12→13 情绪升华进汇聚段,用了闪白 0.2 秒;最后 14→15 收尾淡出转淡入 0.8 秒,品牌感更足。
## 05 音频处理——三类分开做,旁白不拆段
视频画面解决完,最后处理音频。
音频分三类:旁白、环境音、背景音乐,三类逻辑完全不同,分开处理。
旁白:旁白必须整段一次生成,不能按镜头拆成一句一句。拆段生成会导致语速、情绪、语气前后不一致,拼起来接缝明显。正确操作是选好音色后,完整文案一次性生成,再到剪辑软件里按画面时长逐句对准时间点。注意是剪音频对画面,不是剪画面对音频,画面时长不能动。
人物对白(如有):同样整段生成。口型对嘴目前没完美解法,要求不高可以接受,要求高的有两条路:一是直接找真人配音;二是自己先录一遍原声,情绪节奏对上了,再用变声工具替换成目标音色。
环境音:优先在生成视频时同步生成,模型对当前画面的声音判断更准。如果单独补,按每个镜头逐段匹配,不能全程循环同一段背景音。
混音层级:旁白 > 对白 > 环境音 > 背景音乐。背景音乐压到最低,只做氛围托底。
我们怎么做的:
这条广告我们只有人物独白,旁白是整段一次性生成。环境音按场景分开:比如宿舍用自然背景声,洗手间用水声,会议室用空调低频声等等。背景音乐选钢琴,低混不超过旁白音量的 30%。